작물 생산량 예측을 위한 머신러닝 기법 활용 연구
(한국산학기술학회, 2021)

- 3가지 머신러닝 알고리즘으로 작물의 생산량 예측의 적합도를 평가 분석
Ridge Regression, Random Forest, XGBoost
- Ridge Regression : 능선 회귀
선형 독립 변수가 높은 상관관계가 있는 시나리오에서 다중 회귀 모델의 계수를 추정하는 방법
최소제곱법과 매우 유사하나, '각 계수의 제곱을 더한 값'을 식에 포함
계수의 크기도 함께 최소화
- Ridge Regression : 능선 회귀

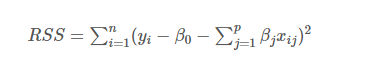
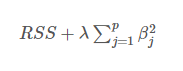
- Random Forest
다수의 결정 트리들을 학습하는 앙상블 방법
검출, 분류, 회귀 등 다양한 문제에 활용 됨 - XGBoost
Gradient Boosting 알고리즘을 분산환경에서도 실행할 수 있게 구현한 라이브러리
Regression, Classification 문제 모두 지원
여러 개의 Decision Tree(결정 트리)를 조합해 사용하는 앙상블 방법
- 실제값과 예측밗의 오차를 산출한 MAE(Mean Absolute Error)/RMSE(Root Mean Square Error)값을 모델 평가 지표로 사용
- MAE(Mean Absolute Error) : 평균 절대 오차
모델의 예측값과 실제값의 차이(절대값)를 모두 더 함
MAE가 높을수록 성능이 낮음
차이의 절대값을 사용하기 때문에 실제값과 음양(-, +)의 차이는 알 수 없음 - MSE(Mean Squared Error) 평균 제곱 오차
모델의 예측값과 실제값 차이의 면적(제곱)의 합
MSE가 높을수록 성능이 낮음
면적으로 계산하기 때문에 특이값에 민감함 - RMSE(Root Mean Square Error) : 평균 제곱근 오차
MSE 값에 루트를 씌운 값
RMSE가 높을수록 성능이 낮음 - R2(R Square; Coefficient of Determination)
R2값이 높을수록 성능이 높음
- MAE(Mean Absolute Error) : 평균 절대 오차
- 최적의 파라미터
Ridge Regression의 파라미터 λ는 2.512
Random Forest의 파라미터는 분할 8, 트리 100
XGBoost의 파라미터는 감마 0, 깊이 10 - 최적 모델 선정
XGBoost가 MAE 0.233, RMSE 0.817로 최소값을 나타내 최적 모델 - 변수의 중요도(출하량 예측)
재식밀도, 1개월차 생장길이 평균값, 2개월차 잎 수의 평균값
요인 선정 방법 : 상관분석(통계 기반), Boruta 알고리즘(머신러닝 기반)- Pearson 상관분석
통계 기반 요인 선정 방법 중 하나로 연속형 요인 간 선형 관계를 확인 - 피어슨 상관계수
두 변수의 선형 상관 관계를 계량화한 수치
결과값은 -1 ~ 1 사이
양의 상관 관계가 있을수록 1에 가깝고, 음의 상관 관계가 있을수록 -1에 가까움
상관관계가 없을수록 0에 가까움. - Boruta 알고리즘
랜덤포레스트 기반으로 변수 선택하는 Wrapper Method(래퍼 방법)
기본적인 아이디어는 기존 변수를 복원 추출해서 만든 shadow(변수)보다 모형 생성에 영향을 주지 못했다고 하면 이는 가치가 크지 않는 변수로 인식하여 제거
- Pearson 상관분석
- XGBoost 모델의 예측력을 R-Square 값을 통해 평가
각 작기별 총 출하량 예측 모델에 대하여 약 77%의 설명력을 보임
Ridge regression(능형 회귀) 간단한 설명과 장점
선형 모델(Linear model)의 예측력(accuracy) 혹은 설명력(interpretability)을 높이기 위해 여러 정규화(regularization) 방법들을 사용한다. 대표적인 shrinkage 방법에는 ridge regression과 lasso가 있으며..
modern-manual.tistory.com
Boruta 알고리즘
변수 선택은 예측 모델을 만드는데 있어서 중요한 단계이다. 데이터의 변수들을 모두 사용하는 것은 과적합(overfitting)을 발생시킬 수 있으며, 많은 시간과 비용이 든다. 실제로, 많은 머신러닝
syj9700.tistory.com


